
Accessors#
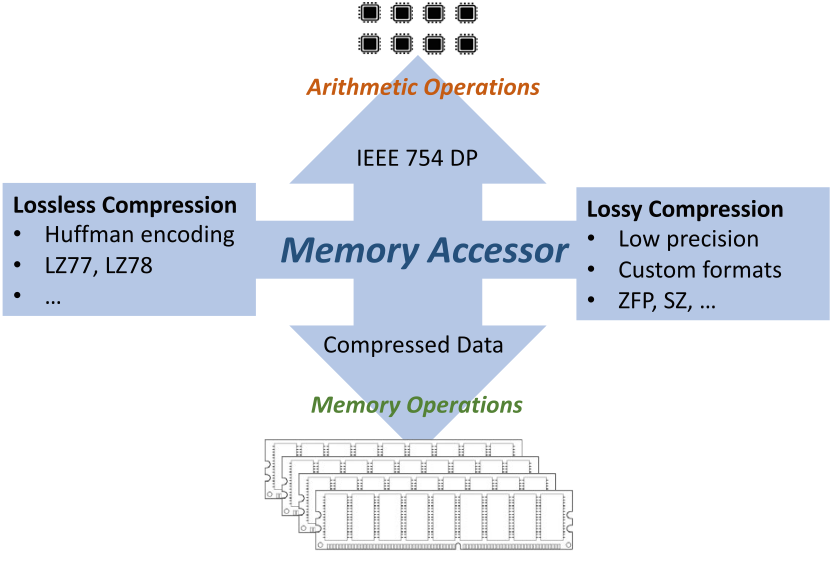
The accessor is a thin layer between arithmetic and memory. Arithmetic happens in a fixed working precision; storage is free to use any layout or compression the accessor implementation can encode and decode on the fly.#
An accessor is a small adapter between a flat memory pointer and an N-dimensional logical view. It owns no memory — it carries the size, the strides, and (for the precision-decoupled variants) the rule for converting between how a value is stored and how it is computed on. Algorithms read and write through an accessor’s operator()(i, j, …) and stay agnostic about the underlying layout, so the same kernel can run against a dense double buffer, a half-precision tile with on-the-fly upcasting, or a scaled low-precision block — without changing its body.
The accessor sub-system lives under accessor/ in the Ginkgo source tree and is exposed in the gko::acc namespace. It is header-only: depending on it costs only an include directory, and it can be lifted into other projects (the companion accessor-BLAS repository is a stand-alone example).
The range wrapper#
gko::acc::range<Accessor> is a thin handle that holds an accessor by value and forwards index calls to it. A range is trivially copyable whenever its accessor is, so it is cheap to pass by value into device kernels.
#include <accessor/range.hpp>
#include <accessor/row_major.hpp>
using sz = gko::acc::size_type;
using acc_t = gko::acc::row_major<double, 2>;
using range_t = gko::acc::range<acc_t>;
double* data = ...; // user-owned buffer
std::array<sz, 2> size{n_rows, n_cols};
std::array<sz, 1> stride{n_cols};
auto r = range_t(size, data, stride);
double v = r(i, j); // read
r(i, j) = 2.0 * v; // write
auto sub = r(gko::acc::index_span{1, 4},
gko::acc::index_span{0, n_cols}); // sub-range, no copy
The accessor headers under accessor/ are header-only and standalone — they are not pulled in by <ginkgo/ginkgo.hpp>. Include the specific accessor you need directly.
Sub-ranges built with index_span share the underlying storage and inherit the parent’s accessor type. The size, the data pointer, and the strides are passed to the accessor in that order; the stride array has length dimensionality − 1 because the innermost dimension is always implicit unit-stride. Sizes and strides are passed as std::array rather than braced initializer lists — template argument deduction on the variadic range constructor doesn’t see through brace-init shortcuts.
Plain layouts#
Accessor |
Dimensionality |
Memory layout |
|---|---|---|
|
D |
row-major; innermost index is contiguous, neighbouring elements along the last axis are adjacent in memory |
|
D ≥ 2 |
the innermost two dimensions are stored column-major; any outer dimensions are row-major over those blocks. Used for blocked matrix formats where each tile is column-major |
Both are constructed from a logical size array, a typed pointer, and a list of D − 1 strides.
Precision-decoupled storage#
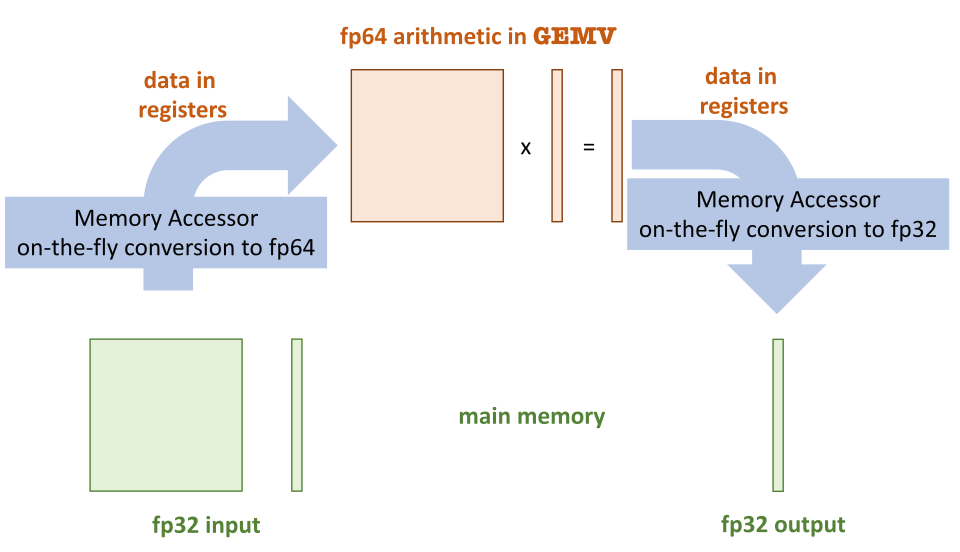
Mixed-precision GEMV with a reduced accessor: fp32 storage in main memory, fp64 arithmetic in registers. The matrix and both vectors stay narrow on the bus; the cast happens transparently on every load and store.#
The reduced_row_major and scaled_reduced_row_major accessors split the type values are stored as from the type they are computed in. The kernel sees one type; memory carries another.
// Store as float, compute as double.
using acc = gko::acc::reduced_row_major</*Dim=*/2,
/*ArithmeticType=*/double,
/*StorageType=*/float>;
using rng = gko::acc::range<acc>;
float* storage = ...;
std::array<sz, 2> size{n_rows, n_cols};
std::array<sz, 1> stride{n_cols};
auto m = rng(size, storage, stride);
double v = m(i, j); // load `float`, cast to `double` on the fly
m(i, j) = 1.5; // accept `double`, cast down to `float` on store
The read and write casts follow standard C++ conversion rules. Float-to-float narrowings round to nearest under the default rounding mode; float-to-integer narrowings (e.g. when storing double into an int8_t-backed reduced accessor) truncate toward zero. For storage choices where that distinction matters, see the mixed-precision how-to on rounding behaviour.
A kernel templated on rng sees only double arithmetic; the memory subsystem moves half the bytes. The arithmetic type is recoverable from the accessor itself:
using ar_type = typename rng::accessor::arithmetic_type; // == double
scaled_reduced_row_major extends this with a per-slice scaling factor. A scalar mask selects which dimensions the scale varies over (for example, one scale per row of a matrix), and read / write paths multiply by — or divide out — that scale automatically. The scale recovers the dynamic range that a naive narrowing would lose, so even ill-conditioned operators where direct truncation to float would underflow or saturate can still be stored at reduced precision.
This is the storage trick that backs Ginkgo’s mixed-precision Krylov solvers; see Mixed precision for how the solver layer exposes it. For stand-alone examples — GEMV, dot, TRSV kernels written entirely against the reduced accessors, with measured accuracy and bandwidth on A100 and V100 — see the accessor-BLAS repository.
Writing accessor-generic kernels#
Template the kernel on the range type and the indexing code stays format-agnostic:
template <typename MtxRange, typename XRange, typename YRange>
__global__ void gemv(MtxRange A, XRange x, YRange y)
{
using ar_type = typename MtxRange::accessor::arithmetic_type;
// Or, deduce from an operation:
// using ar_type = decltype(A(0, 0) * x(0, 0));
const auto row = blockIdx.x;
ar_type sum{};
for (std::int64_t col = threadIdx.x; col < A.length(1); col += blockDim.x) {
sum += A(row, col) * x(col, 0);
}
// … block reduction, then write y(row, 0) = sum
}
The same kernel can be instantiated against:
a plain
range<row_major<double, 2>>— vanilla double-precision GEMV,a
range<reduced_row_major<2, double, float>>—floatstorage withdoublearithmetic,a
range<scaled_reduced_row_major<...>>— scaled low-precision storage,
with no change to the kernel body. The backend type-conversion helpers under accessor/{cuda,hip,cuda_hip,sycl,reference}_helper.hpp map the load / store casts to each target’s intrinsics, so the same source compiles for the reference, CUDA, HIP, and SYCL backends.
When to reach for accessors#
You are writing a kernel that should support more than one storage precision without duplication.
You want to read or write a multi-dimensional view (matrix tile, sub-block of a vector) without materialising a copy.
You are integrating a storage format whose layout does not match a plain row-major buffer —
block_col_majorand custom accessors give you the indexing surface to do that cleanly.
For applications that only need to use mixed-precision solvers — without writing kernels themselves — the accessor layer is an implementation detail; configure the solver via the API described in Mixed precision instead.
See also
Mixed precision — how the solver layer exposes reduced-storage accessors.
accessor-BLAS — stand-alone GEMV / dot / TRSV kernels built on
gko::acc::reduced_row_major, with accuracy and bandwidth plots.