
Heat equation on a distributed grid#
We build a distributed heat-equation solver with Ginkgo and run it on multiple MPI ranks. The problem: a 2D heat-conduction equation on the unit square,
discretised with the 5-point stencil on an \(N \times N\) grid and stepped forward with implicit Euler — so every time step is a linear-system solve with the matrix \(A = I + \tau\,\alpha\,(-\Delta_h)\).
We’ll partition the grid by horizontal stripes, one stripe per rank, assemble the distributed matrix and vectors, and use a Schwarz-preconditioned CG to solve each time step. Output frames are dumped to disk and stitched into a GIF by a short Python post-processor.
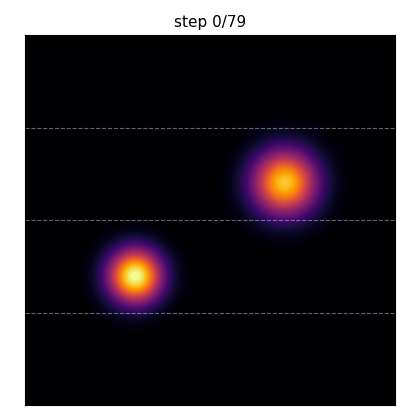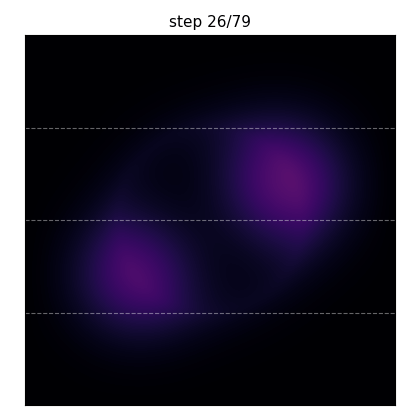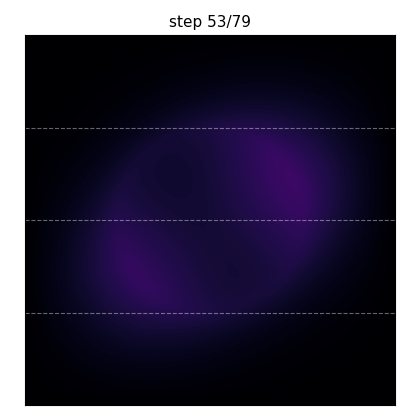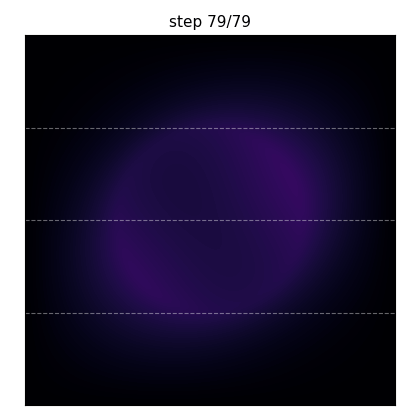
What you’ll produce: two Gaussian hot spots diffusing under a thin annular heat source, simulated with implicit Euler + CG on a \(96\times 96\) grid across 4 MPI ranks. The dashed horizontal lines mark the per-rank boundaries — half the value at a boundary row lives on one rank, half on the next, and the Ginkgo distributed-matrix machinery handles the halo exchange under the hood.#
What you’ll learn#
The minimum surface area for building a
distributed::Matrixanddistributed::Vector(partition →matrix_data→read_distributed).The host-then-device pattern for distributed assembly.
One-level additive Schwarz with a local block-Jacobi solver as a distributed preconditioner.
How to inspect rank-local data via
get_local_vector()for output.A complete, runnable, MPI-parallel time-stepping mini-app.
If you haven’t built anything with Ginkgo before, work through Poisson on CPU first — that tutorial covers the basic solver and matrix-assembly idioms, which we’ll re-use here without re-explaining.
Prerequisites#
You need Ginkgo built with MPI support (-DGINKGO_BUILD_MPI=ON) and a
working MPI installation (OpenMPI, MPICH, etc.). The walk-through below
uses the ReferenceExecutor, so no GPU backend is required — but the same
code runs on OmpExecutor / CudaExecutor / HipExecutor / DpcppExecutor
by changing one line. See Install Ginkgo
for build instructions and Concepts: Distributed computing
for the broader picture.
For the visualization step you also need Python with numpy and
matplotlib (Pillow ships with matplotlib’s GIF writer).
The math, briefly#
Implicit Euler applied to \(\partial_t u = \alpha \Delta u + f\) gives, at each time step,
The 5-point discrete Laplacian on an equidistant grid with spacing \(h\) is
The matrix \(A = I - \tau \alpha \Delta_h\) is SPD with a 5-point sparsity pattern, so CG with a cheap preconditioner converges in tens of iterations per step.
How the grid is distributed#
We flatten the 2D grid in row-major order: cell \((I, j)\) becomes row index
\(r = I \cdot N + j\), so the resulting vector has \(N^2\) entries.
Partition::build_from_global_size_uniform gives each rank a contiguous
chunk of those rows — i.e. a horizontal stripe of the grid. The 5-point
stencil row \(r\) has couplings to rows \(r \pm 1\) (same stripe) and \(r \pm N\)
(possibly on the neighbouring rank), and the
distributed::Matrix splits
those automatically into a diagonal block (entries this rank owns) and an
off-diagonal block (entries on remote ranks). The halo exchange that
SpMV needs is set up once at matrix construction and reused on every
iteration of CG.
horizontal stripes assigned to 4 ranks (N = 96):
columns 0..N-1
┌─────────────────┐
rank 0 │ rows 0..23 │
├─────────────────┤
rank 1 │ rows 24..47 │
├─────────────────┤
rank 2 │ rows 48..71 │
├─────────────────┤
rank 3 │ rows 72..95 │
└─────────────────┘
Project layout#
heat-distributed/
├── CMakeLists.txt
├── heat_distributed.cpp
└── make_gif.py
CMakeLists.txt is the standard recipe plus an MPI dependency:
cmake_minimum_required(VERSION 3.16)
project(heat_distributed CXX)
find_package(Ginkgo REQUIRED)
find_package(MPI REQUIRED COMPONENTS CXX)
add_executable(heat_distributed heat_distributed.cpp)
target_link_libraries(heat_distributed PRIVATE Ginkgo::ginkgo MPI::MPI_CXX)
Walk-through#
Type aliases#
Distributed code needs three index/type concepts that single-rank code doesn’t: a local index type (per-rank addressing), a global index type (across-rank addressing), and a partition type that ties them together.
using ValueType = double;
using LocalIdx = gko::int32;
using GlobalIdx = gko::int64;
using dist_mtx = gko::experimental::distributed::Matrix<ValueType, LocalIdx, GlobalIdx>;
using dist_vec = gko::experimental::distributed::Vector<ValueType>;
using part_t = gko::experimental::distributed::Partition<LocalIdx, GlobalIdx>;
using dense = gko::matrix::Dense<ValueType>;
using cg = gko::solver::Cg<ValueType>;
using schwarz =
gko::experimental::distributed::preconditioner::Schwarz<ValueType, LocalIdx, GlobalIdx>;
using bj = gko::preconditioner::Jacobi<ValueType, LocalIdx>;
int32 for local rows / int64 for global rows is the recommended pair:
on each rank we’ll handle far fewer than \(2^{31}\) rows even on a very
large machine, but the global row count across all ranks can exceed that
easily.
Starting MPI and the executor#
gko::experimental::mpi::environment is the RAII wrapper that calls
MPI_Init / MPI_Finalize for us. Construct it once at the top of
main:
const gko::experimental::mpi::environment env(argc, argv);
const auto comm = gko::experimental::mpi::communicator(MPI_COMM_WORLD);
const int rank = comm.rank();
const int nproc = comm.size();
auto host = gko::ReferenceExecutor::create();
auto exec = host; // swap to OmpExecutor / CudaExecutor / ... for performance
For a GPU run, swap the exec line for
auto exec = gko::CudaExecutor::create(0, host); and the rest of the code
is unchanged. See Concepts: Distributed MPI layer
for the full surface of the MPI wrapper.
Building the partition#
const GlobalIdx num_rows = static_cast<GlobalIdx>(N) * N;
auto partition = gko::share(part_t::build_from_global_size_uniform(
host, nproc, num_rows));
const auto row_start = partition->get_range_bounds()[rank];
const auto row_end = partition->get_range_bounds()[rank + 1];
build_from_global_size_uniform produces a contiguous, near-equal-size
block partition. get_range_bounds() returns the start of every rank’s
range as a flat array, so [rank, rank+1] is this rank’s stripe.
Assembling the local matrix entries#
Each rank fills a matrix_data with only the rows it owns. The
distributed matrix reader will route any off-rank column indices to the
correct neighbour automatically:
const double c_val = diffusion * tau * 4.0 / h2 + 1.0;
const double off_val = -diffusion * tau / h2;
gko::matrix_data<ValueType, GlobalIdx> A_data{gko::dim<2>(num_rows, num_rows)};
for (GlobalIdx r = row_start; r < row_end; ++r) {
const int I = static_cast<int>(r / N);
const int j = static_cast<int>(r % N);
if (I > 0) A_data.nonzeros.emplace_back(r, idx(I - 1, j, N), off_val);
if (j > 0) A_data.nonzeros.emplace_back(r, idx(I, j - 1, N), off_val);
A_data.nonzeros.emplace_back(r, r, c_val);
if (j < N - 1) A_data.nonzeros.emplace_back(r, idx(I, j + 1, N), off_val);
if (I < N - 1) A_data.nonzeros.emplace_back(r, idx(I + 1, j, N), off_val);
}
The idx helper is just I*N + j — row-major linearisation of the 2D
grid. Every entry’s row index r lies in this rank’s range, but the
column indices can land in another rank’s range — that happens at the
top and bottom of the stripe, when I-1 or I+1 crosses a partition
boundary. Those entries become off-diagonal-block entries on this rank
and drive the halo exchange during SpMV.
Initial condition and source term#
The IC is two Gaussian hot spots; the source \(f\) is a thin annulus centred on the grid:
auto u0_at = [N, h](int I, int j) {
const double x = (j + 1) * h;
const double y = (I + 1) * h;
auto blob = [](double x, double y, double cx, double cy, double s, double a) {
const double dx = x - cx, dy = y - cy;
return a * std::exp(-(dx * dx + dy * dy) / (2.0 * s * s));
};
return blob(x, y, 0.30, 0.35, 0.05, 4.0)
+ blob(x, y, 0.70, 0.60, 0.06, 3.5);
};
auto src_at = [N, h](int I, int j) {
const double x = (j + 1) * h;
const double y = (I + 1) * h;
const double dx = x - 0.5, dy = y - 0.5;
const double r = std::sqrt(dx * dx + dy * dy);
return std::exp(-((r - 0.25) * (r - 0.25))
/ (2.0 * 0.012 * 0.012)) * 0.8;
};
Each rank only fills the matrix_data entries for its own rows — there is
no global IC vector ever materialised:
gko::matrix_data<ValueType, GlobalIdx> u_data{gko::dim<2>(num_rows, 1)};
gko::matrix_data<ValueType, GlobalIdx> f_data{gko::dim<2>(num_rows, 1)};
for (GlobalIdx r = row_start; r < row_end; ++r) {
const int I = static_cast<int>(r / N), j = static_cast<int>(r % N);
u_data.nonzeros.emplace_back(r, 0, u0_at(I, j));
f_data.nonzeros.emplace_back(r, 0, src_at(I, j));
}
Read into distributed types#
read_distributed is required to run on a host executor — that’s
where the partition lives and where the routing logic dispatches off-rank
entries. After reading, we copy onto the compute executor (a no-op if the
two are the same):
auto A_host = gko::share(dist_mtx::create(host, comm));
A_host->read_distributed(A_data, partition);
auto u_host = dist_vec::create(host, comm);
auto f_host = dist_vec::create(host, comm);
u_host->read_distributed(u_data, partition);
f_host->read_distributed(f_data, partition);
auto A = gko::share(dist_mtx::create(exec, comm));
auto u_in = dist_vec::create(exec, comm);
auto u_out = dist_vec::create(exec, comm);
auto f = dist_vec::create(exec, comm);
A->copy_from(A_host);
u_in->copy_from(u_host);
f->copy_from(f_host);
u_out->copy_from(u_host); // first apply will overwrite this; the initial-guess content is irrelevant
The Schwarz-preconditioned CG solver#
This is the heart of the distributed-solver pattern. Wrap a single-rank
block-Jacobi inside Schwarz and you get an additive Schwarz
preconditioner that applies the local solve on each rank independently —
no MPI communication during the preconditioner itself. The CG iteration
runs across all ranks, with MPI happening only in the SpMV halo exchange
and in the dot-product / norm reductions:
auto local_solver = gko::share(bj::build().on(exec));
auto solver =
cg::build()
.with_preconditioner(
schwarz::build().with_local_solver(local_solver).on(exec))
.with_criteria(
gko::stop::Iteration::build().with_max_iters(500u),
gko::stop::ResidualNorm<ValueType>::build()
.with_baseline(gko::stop::mode::rhs_norm)
.with_reduction_factor(1e-8))
.on(exec)
->generate(A);
See Distributed solvers and preconditioners for the broader story — including the two-level Schwarz variant and the restrictions on which solvers are validated for distributed runs.
The time loop#
Implicit Euler in three lines:
const auto rhs_scalar = gko::initialize<dense>({tau}, exec);
for (int step = 0; step < n_steps; ++step) {
u_in->add_scaled(rhs_scalar, f); // u_in <- u_in + tau * f
solver->apply(u_in, u_out); // solve A * u_out = u_in
std::swap(u_in, u_out);
// ... periodically dump u_in to disk ...
}
add_scaled is the distributed-vector version of AXPY — it acts on each
rank’s local slice with no MPI traffic. The actual cross-rank communication
happens inside solver->apply, where the SpMV launches the halo exchange.
Dumping frames to disk#
Each rank writes its own stripe per frame — no MPI gather. The Python script reassembles by reading every rank’s file and concatenating in rank order:
auto dump_frame = [&](int frame, const dist_vec* v) {
const auto* vp = v->get_local_vector()->get_const_values();
const auto n_local = static_cast<size_t>(row_end - row_start);
char path[128];
std::snprintf(path, sizeof(path),
"frames/frame_%04d_rank_%02d.bin", frame, rank);
std::ofstream out(path, std::ios::binary);
out.write(reinterpret_cast<const char*>(vp),
static_cast<std::streamsize>(n_local * sizeof(double)));
};
v->get_local_vector() returns a pointer to a matrix::Dense<ValueType>
holding this rank’s slice of the distributed vector. On a GPU executor,
the pointer is to device memory — wrap in gko::clone(host, ...) before
dereferencing, as the
Cross-executor data movement how-to
explains.
Rank 0 also writes a tiny frames/meta.txt recording the grid size,
process count, and partition bounds so the Python script can stitch
without reaching back into the Ginkgo run.
Full program#
heat_distributed.cpp:
#include <cmath>
#include <cstdio>
#include <fstream>
#include <iostream>
#include <vector>
#include <ginkgo/ginkgo.hpp>
using ValueType = double;
using LocalIdx = gko::int32;
using GlobalIdx = gko::int64;
using dist_mtx = gko::experimental::distributed::Matrix<ValueType, LocalIdx, GlobalIdx>;
using dist_vec = gko::experimental::distributed::Vector<ValueType>;
using part_t = gko::experimental::distributed::Partition<LocalIdx, GlobalIdx>;
using dense = gko::matrix::Dense<ValueType>;
using cg = gko::solver::Cg<ValueType>;
using schwarz =
gko::experimental::distributed::preconditioner::Schwarz<ValueType, LocalIdx, GlobalIdx>;
using bj = gko::preconditioner::Jacobi<ValueType, LocalIdx>;
static inline GlobalIdx idx(int I, int j, int N) {
return static_cast<GlobalIdx>(I) * N + j;
}
int main(int argc, char* argv[])
{
const gko::experimental::mpi::environment env(argc, argv);
const auto comm = gko::experimental::mpi::communicator(MPI_COMM_WORLD);
const int rank = comm.rank();
const int nproc = comm.size();
const int N = (argc >= 2) ? std::atoi(argv[1]) : 96;
const int n_steps = (argc >= 3) ? std::atoi(argv[2]) : 1800;
const int n_frames = (argc >= 4) ? std::atoi(argv[3]) : 80;
const double diffusion = 5e-3;
const double h = 1.0 / (N + 1);
const double h2 = h * h;
const double tau = 2e-3;
const double c_val = diffusion * tau * 4.0 / h2 + 1.0;
const double off_val = -diffusion * tau / h2;
auto host = gko::ReferenceExecutor::create();
auto exec = host;
const GlobalIdx num_rows = static_cast<GlobalIdx>(N) * N;
auto partition = gko::share(part_t::build_from_global_size_uniform(
host, nproc, num_rows));
const auto row_start = partition->get_range_bounds()[rank];
const auto row_end = partition->get_range_bounds()[rank + 1];
if (rank == 0) {
std::cout << "grid: " << N << "x" << N
<< ", ranks: " << nproc
<< ", rows/rank ~ " << (num_rows / nproc) << '\n';
}
gko::matrix_data<ValueType, GlobalIdx> A_data{gko::dim<2>(num_rows, num_rows)};
for (GlobalIdx r = row_start; r < row_end; ++r) {
const int I = static_cast<int>(r / N);
const int j = static_cast<int>(r % N);
if (I > 0) A_data.nonzeros.emplace_back(r, idx(I - 1, j, N), off_val);
if (j > 0) A_data.nonzeros.emplace_back(r, idx(I, j - 1, N), off_val);
A_data.nonzeros.emplace_back(r, r, c_val);
if (j < N - 1) A_data.nonzeros.emplace_back(r, idx(I, j + 1, N), off_val);
if (I < N - 1) A_data.nonzeros.emplace_back(r, idx(I + 1, j, N), off_val);
}
auto u0_at = [N, h](int I, int j) {
const double x = (j + 1) * h, y = (I + 1) * h;
auto blob = [](double x, double y, double cx, double cy, double s, double a) {
const double dx = x - cx, dy = y - cy;
return a * std::exp(-(dx * dx + dy * dy) / (2.0 * s * s));
};
return blob(x, y, 0.30, 0.35, 0.05, 4.0)
+ blob(x, y, 0.70, 0.60, 0.06, 3.5);
};
auto src_at = [N, h](int I, int j) {
const double x = (j + 1) * h, y = (I + 1) * h;
const double dx = x - 0.5, dy = y - 0.5;
const double r = std::sqrt(dx * dx + dy * dy);
return std::exp(-((r - 0.25) * (r - 0.25))
/ (2.0 * 0.012 * 0.012)) * 0.8;
};
gko::matrix_data<ValueType, GlobalIdx> u_data{gko::dim<2>(num_rows, 1)};
gko::matrix_data<ValueType, GlobalIdx> f_data{gko::dim<2>(num_rows, 1)};
for (GlobalIdx r = row_start; r < row_end; ++r) {
const int I = static_cast<int>(r / N), j = static_cast<int>(r % N);
u_data.nonzeros.emplace_back(r, 0, u0_at(I, j));
f_data.nonzeros.emplace_back(r, 0, src_at(I, j));
}
auto A_host = gko::share(dist_mtx::create(host, comm));
A_host->read_distributed(A_data, partition);
auto u_host = dist_vec::create(host, comm);
auto f_host = dist_vec::create(host, comm);
u_host->read_distributed(u_data, partition);
f_host->read_distributed(f_data, partition);
auto A = gko::share(dist_mtx::create(exec, comm));
auto u_in = dist_vec::create(exec, comm);
auto u_out = dist_vec::create(exec, comm);
auto f = dist_vec::create(exec, comm);
A->copy_from(A_host);
u_in->copy_from(u_host);
f->copy_from(f_host);
u_out->copy_from(u_host);
auto local_solver = gko::share(bj::build().on(exec));
auto solver =
cg::build()
.with_preconditioner(
schwarz::build().with_local_solver(local_solver).on(exec))
.with_criteria(
gko::stop::Iteration::build().with_max_iters(500u),
gko::stop::ResidualNorm<ValueType>::build()
.with_baseline(gko::stop::mode::rhs_norm)
.with_reduction_factor(1e-8))
.on(exec)
->generate(A);
if (rank == 0) {
std::ofstream meta("frames/meta.txt");
meta << "N " << N << '\n'
<< "nproc " << nproc << '\n'
<< "n_frames " << n_frames << '\n';
for (int r = 0; r <= nproc; ++r) {
meta << "bound " << partition->get_range_bounds()[r] << '\n';
}
}
comm.synchronize();
const auto rhs_scalar = gko::initialize<dense>({tau}, exec);
const int frame_every = std::max(1, n_steps / n_frames);
auto dump_frame = [&](int frame, const dist_vec* v) {
const auto* vp = v->get_local_vector()->get_const_values();
const auto n_local = static_cast<size_t>(row_end - row_start);
char path[128];
std::snprintf(path, sizeof(path),
"frames/frame_%04d_rank_%02d.bin", frame, rank);
std::ofstream out(path, std::ios::binary);
out.write(reinterpret_cast<const char*>(vp),
static_cast<std::streamsize>(n_local * sizeof(double)));
};
int frame_count = 0;
dump_frame(frame_count++, u_in.get());
for (int step = 0; step < n_steps; ++step) {
u_in->add_scaled(rhs_scalar, f);
solver->apply(u_in, u_out);
std::swap(u_in, u_out);
if ((step + 1) % frame_every == 0 && frame_count < n_frames) {
dump_frame(frame_count++, u_in.get());
}
}
if (rank == 0) {
std::cout << "wrote " << frame_count << " frames to frames/" << '\n';
}
}
Build and run#
cmake -B build
cmake --build build
mkdir -p frames
mpirun -np 4 ./build/heat_distributed
Expected output:
grid: 96x96, ranks: 4, rows/rank ~ 2304
wrote 80 frames to frames/
(mpirun syntax is implementation-dependent — on MPICH-based stacks the
command is the same; on some clusters you’ll launch through srun
instead. The arguments to the binary are [N] [n_steps] [n_frames],
defaulting to 96 1800 80.)
After the run, frames/ contains 4 × 80 = 320 binary stripe files plus a
small meta.txt. Each frame is the full \(N\times N\) grid spread across
the ranks; the post-processing script reassembles them.
Building the GIF#
make_gif.py:
#!/usr/bin/env python3
"""Stitch per-rank stripe frames into a single GIF."""
import os, sys
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
frames_dir = sys.argv[1] if len(sys.argv) >= 2 else "frames"
out_path = sys.argv[2] if len(sys.argv) >= 3 else "heat.gif"
with open(os.path.join(frames_dir, "meta.txt")) as f:
meta, bounds = {}, []
for line in f:
p = line.split()
if p[0] == "bound": bounds.append(int(p[1]))
else: meta[p[0]] = int(p[1])
N, nproc, n_frames = meta["N"], meta["nproc"], meta["n_frames"]
per_rank_rows = [bounds[r + 1] - bounds[r] for r in range(nproc)]
frames = []
for k in range(n_frames):
stripes = []
for r in range(nproc):
path = os.path.join(frames_dir, f"frame_{k:04d}_rank_{r:02d}.bin")
data = np.fromfile(path, dtype=np.float64)
stripes.append(data.reshape(per_rank_rows[r] // N, N))
frames.append(np.concatenate(stripes, axis=0))
vmax = max(f.max() for f in frames)
fig, ax = plt.subplots(figsize=(4.2, 4.2))
im = ax.imshow(frames[0], cmap="inferno", origin="lower",
vmin=0, vmax=vmax, interpolation="bilinear",
extent=(0, 1, 0, 1))
ax.set_xticks([]); ax.set_yticks([])
title = ax.set_title("step 0", fontsize=11)
for b in bounds[1:-1]:
y = (b // N) / N
ax.axhline(y=y, color="white", alpha=0.4, linewidth=0.8, linestyle="--")
plt.tight_layout()
def update(k):
im.set_array(frames[k])
title.set_text(f"step {k}/{len(frames) - 1}")
return [im, title]
ani = animation.FuncAnimation(fig, update, frames=len(frames),
interval=80, blit=False)
ani.save(out_path, writer=animation.PillowWriter(fps=15))
print(f"wrote {out_path}")
Run it:
python3 make_gif.py frames heat.gif
The output is the animation embedded at the top of this page. Four-up stills from the same run:
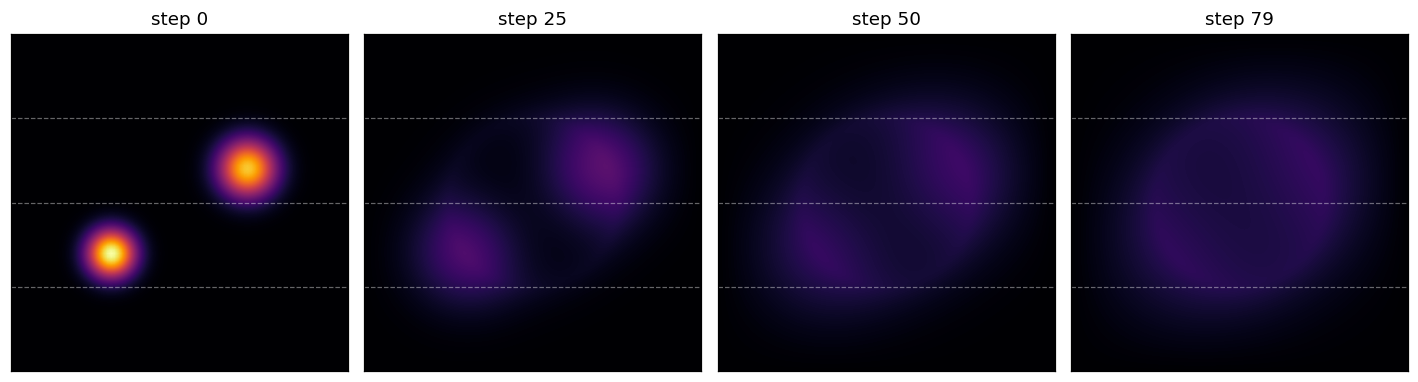
The same run frozen at four steps. The initial hot spots diffuse outward; the annular source term gradually establishes the ring-shaped equilibrium pattern.#
Things to try#
More ranks.
mpirun -np 8works as-is — the partition resizes automatically; the dashed rank-boundary lines in the GIF will tighten.A bigger grid.
mpirun -np 4 ./build/heat_distributed 192doubles the grid resolution. With \(N = 192\) the system is \(36{,}864 \times 36{,}864\) but the per-iteration cost only grows linearly in \(N^2\).A different IC. Edit
u0_atto draw whatever shape you like; a sharp letter, a checkerboard, or a single point.A GPU executor. Change the
execline togko::CudaExecutor::create(0, host)(and rebuild with CUDA support). The rest of the code, including the MPI communication, is unchanged.Two-level Schwarz. Add a coarse correction by setting
with_coarse_level(...)andwith_coarse_solver(...)on the Schwarz factory — see Distributed solvers and preconditioners — two-level Schwarz.
Pitfalls#
read_distributedinsists on a host executor. The data routing logic runs CPU-side. Build withhost, thencopy_fromonto the compute executor — exactly the pattern shown above.Per-rank file output races. With 4 ranks and 80 frames per rank that’s only a few hundred small files; with thousands of ranks the filesystem will object. Production codes batch into shared collective-write formats (HDF5, ADIOS) — for tutorials the simple pattern is fine.
Don’t dereference a device pointer on the host. If you switch
execto a GPU executor, the local vector returned byget_local_vector()lives on the device; copy withgko::clone(host, ...)before writing it out.Two distinct meanings of “diagonal”. Ginkgo’s distributed-matrix vocabulary uses diagonal matrix for the block of entries this rank owns (rows and columns both local) and off-diagonal matrix for the entries with remote columns. Both are sparse blocks; neither is a literal diagonal-of-the-matrix in the linear-algebra sense. The worked example on the distributed page walks through this on a tiny 4x4 system.
Next steps#
Concepts: Distributed computing — the global picture, including assembly, partition, and index maps.
Concepts: Distributed solvers and preconditioners — which Krylov methods are distributed-ready, plus one- and two-level Schwarz in detail.
Concepts: Communication primitives — what’s happening under the hood during
solver->apply.Poisson on CPU and Poisson on GPU — the single-rank tutorials that introduce the matrix-assembly and executor patterns used here.
See also
gko::experimental::distributed::Matrix— full API reference.gko::experimental::distributed::preconditioner::Schwarz— the one- and two-level Schwarz preconditioner reference.Upstream
examples/heat-equationandexamples/distributed-solver— the source examples this tutorial is derived from.